 Image
credit: Sunshine by
AlteredQualia
Image
credit: Sunshine by
AlteredQualiaHolograms, realism, or simply goodbye uncanny valley
As early as the 1980s, popular cinema and television began depicting holograms of the future. These transparent blue figures have been a great influence on our perceptual model of what holograms should look like. Nowadays, innovation in machine learning, computer graphics, and hardware are paving the way for holographic content to become mainstream, and, yet, some of the questions I still ask myself are: Why are we so obsessed with realism? What is the archival benefit of documenting humans in 3D? What is the connection between holograms and personal assistants?
 Image credit:
AlteredQualia / Branislav Ulicny Uncanny
Valley WebGL experience
Image credit:
AlteredQualia / Branislav Ulicny Uncanny
Valley WebGL experienceLet's examine the idea of the uncanny valley. The uncanny valley term was coined by Masahiro Mori and presented in Jasia Reichardt’s book Robots: Fact, Fiction, and Prediction.
In aesthetics, the uncanny valley is a hypothesized relationship between the degree of an object’s resemblance to a human being and the emotional response to such an object [Karl F. MacDorman & Hiroshi Ishiguro].
This idea is perhaps best suited to describe not a phenomenon but an era, which we are arguably transitioning out of. With smarter software becoming ubiquitous in almost every aspect of our lives, we are (consciously or not) building things that behave and react more like us. When we emphasize function over imitative visuals we tend to avoid that uncomfortable “uncanny valley” feeling. Is Amazon’s Alexa or Google Home uncanny? I would argue not since speech generation has become convincing enough paired with pure functional use:
Me: Alexa, put something on my shopping list Alexa: Ok.
Perhaps the uncanny valley is a result of the transition from 2D to 3D imagery and will no longer be needed once holograms become convincing enough, alongside playing a functional role in our lives.
Our lives are surrounded by interfaces, apps, physical signage, and, more recently, voice interfaces such as Alexa and Google Home. These interfaces are meant to serve a specific function in our day-to-day lives but, more often than not, they look, feel, and sound nothing like us. With more and more demand for computer-generated imagery (CGI) in recent years, and the popularization of platforms such as augmented and virtual reality, computer games, and interactive filmmaking, it is clear there is a potential for new human-computer interfaces that also resemble us visually.
There is a potential for new human-computer interfaces that also resemble us visually.
To create that, companies, and artists are exploring various forms of 3D capturing meant to replicate the human element, in new and compelling ways beyond two-dimensional pixels. These tools are what forms the basis for volumetric capturing, a collection of techniques for capturing three-dimensional humans.
These tools are not born in a vacuum. Some are born from a product vision, such as Intel’s Replay technology for 3D sports, which engages sports fans in a new way by allowing them to replay a move from different angles. Other tools are born from computational aesthetic explorations, such as Scatter’s Depthkit, which was initially developed in order to create CLOUDS, a volumetric documentary about creative uses of software. One thing all of the tools share is the visual, technical, and anthological exploration of how to represent and document real humans in 3D space.
 Image
credit: Intel
TrueView
Image
credit: Intel
TrueViewDuring my thesis research in ITP, I focused on the possibilities of using machine learning to reconstruct archival and historical footage in 3D. The idea of using machine learning was born out of a desire to look back into more than 200 years of visual culture (i.e. 2D photography) and speculate about how we can bridge the growing gap between 2D and 3D.
Recently, Apple has included a depth sensor into the new iPhones. Facebook now lets you post 3D photos to your wall. And Snapchat has augmented reality facial filters. These are only a few examples of recent spatial interfaces invading our daily lives. My research has led me to believe that we are in a moment of acute awareness of the transition from 2D to 3D. Even though some might argue that we have already entered the 3D era, it seems to me that this is only the tip of the iceberg. Look back at the transition from black and white to color, from analog film to digital, and, through that lens, think about the transition from 2D to 3D. This is nothing short of a revolutionary cultural moment.
For example, today, black and white imagery is used to symbolize authenticity and age, but before the widespread availability of color photography, it was considered a representation of current reality. So how will we look back at two-dimensional media a hundred years from now? Will it only be a testimony of our past, or can we bridge the gap by using new technologies?
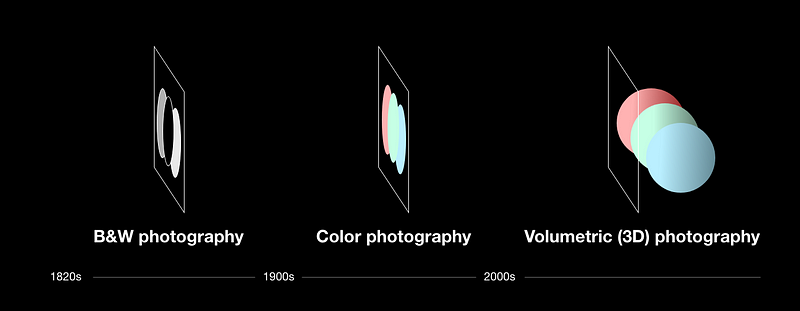 The
evolution of photography, Image credit: Volume
The
evolution of photography, Image credit: Volume
Machine learning advancements have made it possible to relive films in a way that generates compelling results. For example, as a part of my thesis research, together with Shirin Anlen, we reconstructed a scene from Pulp Fiction in augmented reality. This example used machine learning to separate the characters from the background and generate volumetric figures that are then used in the augmented reality scene.
Volumetric capturing?
There are a wide variety of techniques, which range from laser scanning (also referred to as LIDAR scanning), infrared sensors (a notable example is Microsoft’s Kinect camera) and, most recently, the use of machine learning and convolutional neural networks to reconstruct a 3D object from 2D images (as shown in the above Pulp Fiction example). These methods all have roots in different fields such as defense, robotics, and topology but are now being used more and more for art, entertainment, and media.
 Image
credit: Marshmallow Laser Feast MEMEX | Duologue on
Vimeo
Image
credit: Marshmallow Laser Feast MEMEX | Duologue on
VimeoComputational humans? Alexa gets a body
Innovation in machine learning doesn’t only affect the fidelity of the 3D acquisition and rendering process but also provides ground for procedurally generated facial expressions and dialog which bears an amazing resemblance to us, the human counterpart. For example, Hao Li, Director of the Vision and Graphics Lab at USC and founder of Pinscreen, published research showing the ability of a Generative Adversarial Networks (GANs) to reconstruct a 3D facial model from a 2D image, which can then be puppeteered.
Popular entertainment is also taking note. In order to create facial expressions behind Thanos in Marvel’s Avengers films, VFX studio, Digital Domain, created machine-learning-driven software, called Masquerade, that aids artists in creating compelling facial expressions. Imagine Google’s Duplex demo, combined with the facial expressions produced by the Masquerade software — personal assistants are given a big facelift, well, quite literally.

After watching some of these tech demos, I found myself engaged in a conversation about the nature of personal assistants with Dror Ayalon. An interesting point arose in that we are experiencing a transition from personal assistants morphing into personal companions. The idea of embodying that voice that keeps our Amazon shopping lists, turns the lights on, and sets a timer during our spontaneous decision to cook is yet another step towards Alexa getting a body and becoming almost human.
We are experiencing a transition from personal assistants morphing into personal companions.
Films have already imagined this idea, and it seems there is still a way to go before we can get to the vision portrayed in Her where Alexa sounds like Scarlett Johansson and helps you win a holographic video game.
There is an argument to be made that Alexa doesn’t necessarily have to look like us. Take, for example, Anki’s Vector robot, which provides a very compelling experience without some of the visual human features; it feels like a physical embodiment of Pixar’s communication of emotion through sounds and facial expressions.
That said, a human representation could stretch beyond novelty and utility into something that resembles a relationship, not just “Order more toilet paper.”
Alexa, stop!
All this said and done, it seems spatial computing, volumetric capturing, and voice interfaces are becoming interconnected and are on a track to disrupt our perception of the uncanny valley. Personally, I am really excited about the possibilities in software interfaces becoming, well, a little more like us, and a little less like this.
 Scrolling —
From Giphy
Scrolling —
From Giphy
Immerse is an initiative of the MIT Open DocLab and The Fledgling Fund, and it receives funding from Just Films | Ford Foundation and the MacArthur Foundation. IFP is our fiscal sponsor. Learn more here. We are committed to exploring and showcasing media projects that push the boundaries of media and tackle issues of social justice — and rely on friends like you to sustain ourselves and grow. Join us by making a gift today.